Pyramid supports various SQL schema designs to optimize data organization and query performance. These are reflected in the data and semantic models.
Schema Types
Below is a description of the three most common schema models.
Star Schema
A simple, high-performance design where a central fact table links directly to multiple dimension tables. This structure enables fast queries and easy reporting, but usually requires some denormalization of the data structures.

Snowflake Schema
Snowflake schemas are an extension of the Star Schema where dimension tables are more normalized into multiple related tables. This reduces redundancy and storage costs while maintaining strong analytical capabilities. Snowflake schemas tend to be more realistic, since its most data stores have some degree of normalization.
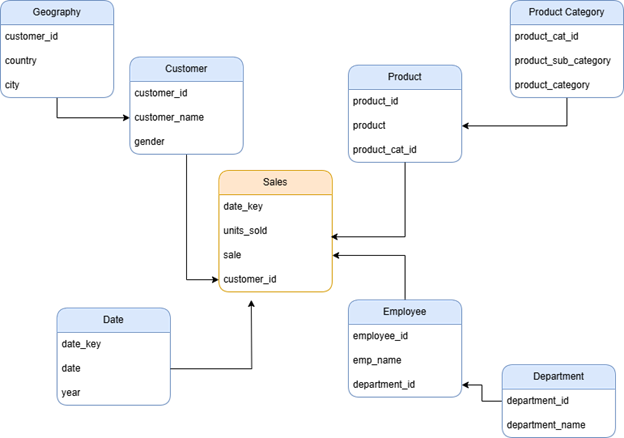
Diamond Schema
The Diamond Schema is a data modeling design where dimension tables are connected to multiple fact tables, forming a structure that resembles a diamond. This approach allows for greater flexibility in linking dimensions to different types of facts, enabling more complex analytical needs. By connecting dimensions to more than one fact table, the schema supports a variety of analysis scenarios, while also optimizing performance by balancing normalization and denormalization within the design.
Diamond schemas are supported in Pyramid, but we recommend using them only when they are analytically necessary. Since diamond schemas create multiple connection paths between tables, the PYRANA query engine must determine joins heuristically for different query variations.
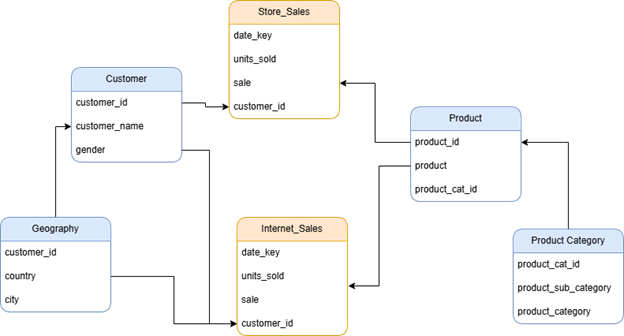
For example, using the below diagram, when querying Geography.country and Product.product, Pyramid selects the ‘shortest path’—in this case, through the ‘Internet_Sales’ table. However, this heuristic approach to query shaping can sometimes result in unexpected performance outcomes or query results.
Optimizing Relationship Joins
For best performance, relationship joins in all schema types should aim to be:
- Perfect - i.e. inner joins that have no missing data elements on either side
- Integer based -versus other data types
- Single key - i.e. it should not require the joining of 2 or more columns to create the relationship